大数据开发离不开各种框架,我们通过学习 Apache Hadoop、Spark 和 Flink 之间的特征比较,可以从侧面了解要学习的内容。众所周知,Hadoop vs Spark vs Flink是快速占领 IT 市场的三大大数据技术,大数据岗位几乎都...
”flink 安全 大数据 hadoop java“ 的搜索结果


├─01-大数据之Flink框架 - Java.doc ├─01-大数据之Flink框架 - Scala.doc (2)\2.资料;目录中文件数:0个 (3)\3.代码;目录中文件数:2个 ├─flink-java-code.zip ├─flink-scala-code.zip (4)\4.视频;目录中文...
在做流计算时spark只能用批处理模拟流模型,因此flink的流计算略快于spark。Hive:本身并不存储数据,可以理解为是一个编程接口,将SQL语句转化成对HDFS的命令。底层来看,spark效率更高。Spark:计算框架,可以实现...

flink 1.14.3集成hadoop 3.2.3的jar包,flink启动yarn session时需要将该jar放到flink的lib目录下
flink提交作业和执行任务,需要几个关键组件:客户端(client):代码由客户端获取并作转换,之后提交给 jobManagerJobManager:就是flink集群里的“管事人”,对作业进行中央调度管理;
随着大数据时代的来临,处理和分析海量数据成为了一项重要的挑战。在大数据系统中由于其存储采用了分布式的架构,计算任务不再是单点的,而是分布式的,是要分发到集群中的各个存储节点上去的,由各个结点计算后汇总...


1.大数据概述1.1.大数据的概念大数据即字面意思,大量数据。那么这个数据量大到多少才算大数据喃?通常,当数据量达到TB乃至PB级别时,传统的关系型数据库在处理能力、存储效率或查询性能上可能会遇到瓶颈,这时考虑...
- 关闭yarn内存检查 flink on hadoop 配置-->-- 指定HDFS中NameNode的地址 默认 9000端口-->-- 指定Hadoop运行时产生文件的存储目录 -->-- 2nn web端访问地址 可以不配置-->-- 历史服务器web端地址 -->


flink提交作业和执行任务,需要几个关键组件:客户端(client):代码由客户端获取并作转换,之后提交给 jobManagerJobManager:就是flink集群里的“管事人”,对作业进行中央调度管理;
在本文中,我们将对 Apache Hadoop、Spark、 Flink三者之间的功能进行比较。它们都是大数据处理技术,以各种特色和优势迅速占领了IT大数据处理市场。本文您将了解Spark所针对的Hadoop的局限性以及由于 Spark的缺点而...
# 解压命令 tar -zxvf flink-shaded-hadoop-2-uber-3.0.0-cdh6.2.0-7.0.jar.tar.gz # 介绍 用于CDH部署 Flink所依赖的jar包
Apache Flink是一个开源的流式数据处理框架,支持高性能、可扩展、容错的分布式流处理应用。
Hadoop是大数据开发的重要框架,是一个由Apache基金会所开发的分布式系统基础架构,其核心是HDFS和MapReduce,HDFS为海量的数据提供了存储,MapReduce为海量的数据提供了计算,在Hadoop2.x时 代,增加 了Yarn,Yarn...


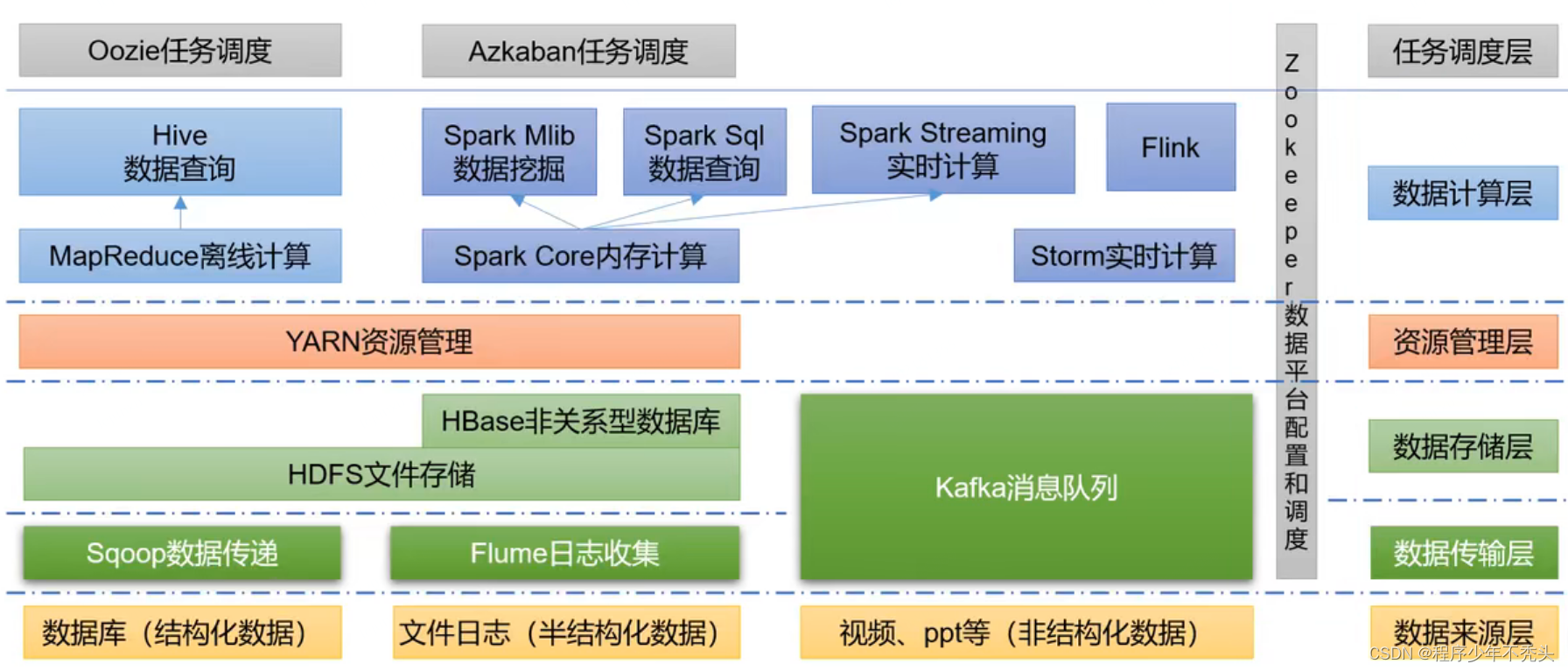
大数据生态知识体系

flink-1.11 版本后不带连接hadoop的jar包,需要自己手动编译打包,这里我将自己使用的 jar包分享给有需要的人。
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mH0U4e1A-1641888708908)(day01_hadoop.assets/1628589606864.png)]简单来说大数据就是海量数据及其处理。大数据(big data),指无法在一定...



推荐文章
- 阿里云企业邮箱的stmp服务器地址_阿里云stmp地址-程序员宅基地
- c++ 判断数学表达式有效性_高考数学大题如何"保分"?学霸教你六大绝招!...-程序员宅基地
- 处理office365登录出现服务器问题_o365登陆显示网络异常-程序员宅基地
- Nginx RTMP源码分析--ngx_rtmp_live_module源码分析之添加stream_ngx_rtmp_live_module 原理-程序员宅基地
- 基于Ansible+Python开发运维巡检工具_automation_inspector.tar.gz-程序员宅基地
- Linux Shell - if 语句和判断表达式_shell if elif-程序员宅基地
- python升序和降序排序_Python排序列表数组方法–通过示例解释升序和降序-程序员宅基地
- jenkins 构建前执行shell_Jenkins – 在构建之前执行脚本,然后让用户确认构建-程序员宅基地
- 如何完全卸载MySQL_mysql怎么卸载干净-程序员宅基地
- AndroidO Treble架构下HIDL服务查询过程_found dead hwbinder service-程序员宅基地